 Jeffrey Tse's Blog
Jeffrey Tse's Blog
The Handbook of System Design
The right architecture = Coming up potential solutions + Managing trade-offs
System design is the process of defining the architecture, interfaces, and data for a system that satisfies specific business requirements. A good system design requires engineers to think about everything in an infrastructure, from the hardware/software, down to the data and how it’s stored.
As a senior software engineer, you are demanded a better understanding of how you solve a particular design problem, how you respond when there is more than expected traffic on your system, how you design the database of your system and many more.
Basic
All design decisions are based on below 4 factors:
- Scalability
- Reliability
- Availability
- Maintainability
Do remember: Everything is a trade-off.
The right architecture = Coming up potential solutions + Managing trade-offs
About trade-off:
- All architectures start from requirements. When one person maintains several microservices, you will go crazy.
- Under the premise of meeting the requirements, the simpler the implementation, the better.
- Execution performance and development efficiency are a pair of contradictions
in software development.
- Performance issues are troubles after success, while development efficiency is a problem that is faced on the first day of the project.
- Most projects die before they encounter performance problems.
- The moment the product faces the user, you may only begin to know exactly what the user needs, so let’s launch it as soon as possible.
- The cost of people is always the highest, leave the thinking time to yourself, and leave the hard work to the machine.
- The main problems faced at different stages are different. It is the right choice to seek a quick solution to the problem. No application architecture is ever the same.
- Don’t optimize prematurely. In actual projects, you can find the most time-consuming places to optimize.
- Consistency, sometimes not so important, can be sacrificed in exchange for
performance.
- If it is a stateless service, such as a general API service, you don’t need to consider CAP. The consistency is generally guaranteed by the later storage. For very critical places, you can deal with it according to the specific situation.
Approaching a Design Problem:
- Breaking down the problem
- Communicating your ideas
- Assumptions that make sense
Approaching
To approach a system design, you need to ensure in a systematic way (mainly according to the Software Engineering).
For interview, The purpose of this section is to assess a candidate’s experience in designing large scale distributed systems. In general, there are 4 steps to solve a system design problem:
- Understand the problem and clarify exact design scope (10%)
- Clarify requirements (functional & non-functional)
- Functional requirements could go in different directions depending on the goals of the interviewer.
- Non-functional requirements should always be assumed a large scale distributed system which handles hundreds of thousands of concurrent requests, request latency is low and the system requires big storages.
- Sketch the high-level design and get buy-in (30%)
- Design deep dive (25%)
- Articulate the problem
- Discuss database & storage layer
- Discuss core components
- Add in high availability considerations
- Come up with at least two solutions
- Discuss the trade-offs of the solutions
- Pick up a solution and discuss it
- Repeat the process with another dive topic
- Articulate the problem
- Wrap up (10%)
- Summarize the design, here we should focus on the parts that are unique to the particular situation, and keep this short and sweet.
- Ask some questions about the company.
Moreover, do remember the below tips:
- You’re expected to take the ownership and lead the discussion. Hence, you should be active to deliver the information and clarify with the interviewer which directions they want you to go further.
- As system design interview questions are open-ended and unstructured, you should organize your solution with a clear plan and justify the choices for the sake of better chances of success.
Requirements Analysis/Clarifications
Outline the scope of the system, and come out SRS (Software Requirements Specification). This includes gathering information about the problem space, performance requirements, scalability needs, and security concerns.
- Background
- Why do we need to build the system?
- What kind of problems does the system solve?
- …
- Functional Requirements (Use cases, systems exist to solve specific problems)
- Include business rules, authentication, administrative functions, authorization levels, etc.
- Examples
- Who is going to use it?
- How are they going to use it?
- What does the system do?
- What’s the format of the input data?
- Should users be able to register an account, delete an account and recover the password?
- …
- Non-functional Requirements (Constraints, restrict the system design through
different qualities)
- The more senior the role is, the more important it is for us to demonstrate our ability to handle non-functional requirements.
- Include performance, security, reliability, scalability, maintainability,
availability, consistency, freshness, accuracy, etc.
- Focusing on scale and performance
- Mainly identify traffic and data handling constraints at scale.
- Scale of the system such as requests per second, requests types, data written per second, data read per second)
- Special system requirements such as multi-threading, read or write oriented.
- Examples
- High availability
- Service has high availability 99.999%
- It should be highly available no matter what operation you perform (expanding storage, backup, when new nodes are added, etc)
- Consistency
- Strong consistency
- Weak consistency
- Eventual consistency
- Low latency
- A latency of around 300ms for timeline generation
- Under 150 milliseconds for viewing pages
- Under 400 milliseconds for conducting searches
- Scale
- Serves 10 million users
- 150 million of DAU (Daily Active Users)
- Security
- Prevent from DDos attacks (WAF, Web Application Firewall)
- …
- High availability
- Assumptions (Estimation of important parts, do some rough
back-of-the-envelope calculation here)
- Storage
- How many files would be upload daily?
- Examples
- Videos 5MB per video * 2 = 10MB/day/user
- Users meta data 1K/user/day
- Bandwidth
- Ingress (write bandwidth)
- 50TB per day ~= 500MB/s
- Egress (read bandwidth)
- ~= 100x write access ~= 50GB/s
- Ingress (write bandwidth)
- Traffic
- W/R QPS(Queries per second) = 150 millions * 0.2
- RAM
- At 1M concurrent users, assuming each user connection needs 10K of memory on the server, about 10GB of memory to hold all the connections
- …
- Storage
- Data Flows (Data models and data flows between them)
- Database (Choose database system is also part of this)
- Database Indexes
- A database index is used for the purpose of speeding up reads conditioned on the value of a specific key.
- Be careful to not overuse indexes, as they slow down database writes.
- Two main types
- LSM Trees + SSTables
- Writes first go to a balanced binary search tree in memory
- Tree flushed to a sorted table on disk when it gets to0 big
- Can binary search SSTables for the value of a key
- If there are too many SSTables they can be merged together (old values of keys will be discarded)
- Pros
- Fast writes to memory
- Cons
- May have to search many SSTables for value of key
- B-Trees
- A binary tree using pointers on disk
- Writes iterate through the binary tree and either overwrite the existing key value or create a new page on disk and modify the parent pointer to the new page
- Pros
- Faster reads, know exactly where key is located
- Cons
- Slow writes to disk instead of memory
- LSM Trees + SSTables
- How to choose the right database?
- Consideration from aspects
- Performance
- CPU
- Memory
- I/O
- Network
- Query tuning
- Limitations
- The page size limit
- SQL Join is not supported
- Doesn’t provide read-after-write consistency
- Others
- Benchmark, pay attention to the outliers, the average is not meaningful.
- Find the hidden cost of effortless horizontal scalability
- Performance
- Bad choice
- Extend downtime
- Customer impact
- Data lost
- Consideration from aspects
- Relational DB (SQL DB)
- You’re building the first version of your system and aren’t completely sure about the data access patterns
- You want to maintain zero data redundancy
- When correctness and consistency is of more importance than speed
- Key features
- Relational/Normalized data - changes to one table may require others
- E.g. adding an author and their books to different tables on different nodes, may need two phases commit (Expensive)
- Have transactional (ACID guarantees)
- Excessively slow if you don’t need them (due to two phase locking)
- Typically use B-trees
- Better for reads than writes in theory
- Relational/Normalized data - changes to one table may require others
- Products
- Amazon RDS
- Non-relational DB (NoSQL DB)
- This is a good option if your data model has no fixed schema
- Types
- Key-value DB
- Products
- Amazon DynamoDB
- Products
- Document DB
- Products
- MongoDB
- Key features
- Documented data model (NoSQL)
- Data is written in large nested documents, better data locality (if you choose to organize your data in a way that take advantage of this), but denormalized
- B-trees and transactions supported
- Documented data model (NoSQL)
- Rarely makes sense to use in a system design interview since nothing is “special” about it, but good if you want SQL like guarantees on data with more flexibility via the document model
- Key features
- Amazon DocumentDB
- Apache Cassandra (Started by Facebook in 2008)
- Key features
- Wide-column data store (NoSQL), has a shard key and a sort
key
- Allow flexible schemas ease of partitioning
- MultiLeader/Leaderless replication (configurable)
- Super fast writes, albeit uses last write wins for conflict resolution
- May clobber existing writes if they were not the winner of LWW
- Index based off of LSM trees and SSTables
- Fast writes
- Uses LSTM rather than B+ Tree used by SQL
- Wide-column data store (NoSQL), has a shard key and a sort
key
- Benefits of a wide-column NoSQL database include speed of querying, scalability, and a flexible data model.
- Great for application with high write volume, consistency is not as important, all writes and reads go to the same shard (no transactions)
- Key features
- MongoDB
- Products
- Graph DB
- Graph databases are a good idea when you have many many-to-many relationships.
- Products
- Amazon Neptune
- Neo4j
- In-memory DB
- Products
- Redis
- Key features
- Key-value stores implemented in memory (Redis a bit more
feature rich)
- Uses hashmap under the hood
- Good for caches, certain essential app feature
- Key-value stores implemented in memory (Redis a bit more
feature rich)
- Useful for data that needs to be written and retrieved extremely, memory is expensive so good for small datasets
- Key features
- Amazon MemoryDB
- Memcached
- Redis
- Products
- Time-series DB
- Search DB
- Key-value DB
- Trade-off
- Measures
- What type of data are we going to be storing?
- Do we need normalization and joins to reduce data redundancy?
- …
- For choosing SQL
- Much less space compared with NoSQL
- For choosing NoSQL
- Consistency is not as important as availability : Netflix is not a banking application so this is a huge factor. ACID is also not as important.
- Normalization is not that complex in systems like Netflix. They’re not Online Transaction Processing (OLTP) apps like banking apps, NoSQL scale immensely with static models that don’t change much.
- If models DO require that rare change -> SQL involves some sort of downtime. NoSQL has a distinct advantage here. (This was cited as one of the reasons for moving away from SQL)
- Much higher scale, as they often claim to support near linearly horizontal scalability
- Eliminate or limit transactional guarantees (ACID)
- Severely limit data modeling flexibility. There are no data queries across data entities, the data is highly denormalized where the same piece of data is stored in many collections to support different data access patterns.
- The disadvantage of this option is the difficulty in handling complex relationship queries, storing redundant data and more expensive than relational databases.
- Measures
- Database Indexes
- Storage
- Block storage
- A hight-performance block storage for both throughput and transaction- intensive workloads at scale
- Products
- Amazon Elastic Block Store (EBS)
- File storage
- A file system for you to share file data without managing storage
- Products
- Amazon Elastic File System (EFS)
- Object storage
- A storage for you to store and retrieve any amount of data from anywhere
- Products
- Amazon Simple Storage Service (S3)
- Redundant Disk Arrays (RAID)
- Block storage
- File systems
- Google File System (GFS)
- Hadoop Distributed File System (HDFS)
- Message queues (Pub/Sub)
- RabbitMQ
- Kafka (a messaging system for LinkedIn but has since grown to become a popular distributed event streaming platform)
- …
- Database (Choose database system is also part of this)
Related Tools:
- Data Flow Diagram (DFD)
- Data Dictionary (DD)
- Decision Trees
- Decision Tables
- …
Related Constraints/Bottleneck:
- The average QPS of a single machine can reach 800-1000.
- The average R/W speed of HDD is 60-80MB/s.
- …
System Design
The system design phase is the process of defining the architecture, components, modules, interfaces, and data for a system to satisfy specified requirements. It involves making high-level design decisions about the overall structure and organization of the system, as well as low-level design decisions about the specific implementation of the components and modules.
System Architecture Design
System architecture design is the process of defining the overall structure and organization of a system, including the major components and their interactions.
It consists of 3 main layers:
- Conceptual Architecture (System Overview of HLD for Proposal Review)
- Purpose
- The highest level of abstraction, provides a broad overview of the system and its components.
- Only focuses on static structure and functions of the system, in other words, whether A and B are existing rather than how the data flows between them
- Answer questions
- What are the major components of the system?
- What are the layers of the system?
- What are the external systems that the system interacts with?
- Proposal review
- Diagrams
- Layered Architecture Diagram
- System Context Diagram (SCD)
- Container Diagram
- Components
- Major system components
- Technology route
- General Content
- Portal
- Infrastructure
- Core components
- Data storage
- …
- Stakeholders/Audience
- Customers
- CTO
- Product Managers
- Product Owners
- …
- Purpose
- Logical/Functional Architecture (Interaction Logic of HLD for Technical Review)
- Purpose
- The second level of abstraction, provides a more detailed view of the system and its components, including their interactions and relationships.
- Focuses on the dynamic behaviors and interaction logic between components
- Answer questions
- How do the components interact with each other?
- How does the data flow between components?
- Technical review and evaluation
- Diagrams
- Component Diagram
- Data Flow Diagram (DFD)
- Components
- High cohesion and low coupling for the independence of components
- Divide by functions
- Divide by domains
- General Content
- Component relationship
- Scale the design (Scale problems)
- Stakeholders/Audience
- Architects
- Technical Leads
- Software Engineers
- …
- Purpose
- Detail Architecture (Implementation Details of LLD for Development Guidance)
- Purpose
- The lowest level of abstraction, provides a detailed view of the system and its components, including their specific implementation details.
- Focuses on the specific implementation details of the components and modules, such as interfaces, algorithms, processes, state transitions, etc.
- Answer questions
- What are the specific implementation details of the components and modules?
- How do the components and modules interact with each other at a low level?
- How do the components and modules handle specific scenarios and edge cases?
- Development guidance and implementation
- Diagrams
- Class Diagram
- Sequence Diagram
- Activity Diagram
- State Diagram
- Database Schema Diagram
- API Design Diagram
- Data Model Diagram
- …
- Components
- Interface
- Algorithm
- Process
- State transition
- …
- General Content
- System API design
- Database schema design
- Class diagram design
- Function Call diagram design
- Data Dictionary design
- …
- Stakeholders/Audience
- Software Engineers
- Software Testers
- …
- Purpose
High-Level Design (HLD, known as General Design, Architectural Blueprint)
Outline a high level architecture design, such as identifying the major system components, choosing appropriate technology route.
Conceptual Design
Conceptual design is the process of defining the overall structure and organization of a system, including the major components and their interactions. It is a high-level design that focuses on the overall architecture and organization of the system, rather than the specific details of how the components will be implemented.
- Identify the major system components
- For example, for a web application, the major components could be:
- Frontend (Web/Mobile)
- Backend (API Server)
- Database
- Cache
- Load Balancer
- CDN
- Message Queue
- …
- For example, for a web application, the major components could be:
- Choose appropriate technology route
- For example, the major components could be:
- For the backend, we can choose to use Java Spring Boot, Python Django, Node.js Express, etc.
- For the database, we can choose to use MySQL, PostgreSQL, MongoDB, etc.
- For the cache, we can choose to use Redis, Memcached, etc.
- For the load balancer, we can choose to use Amazon Elastic Load Balancing (ELB), Nginx, etc.
- For the CDN, we can choose to use CloudFlare, Fastly, Amazon CloudFront, etc.
- For the message queue, we can choose to use RabbitMQ, Kafka, etc.
- …
- For example, the major components could be:
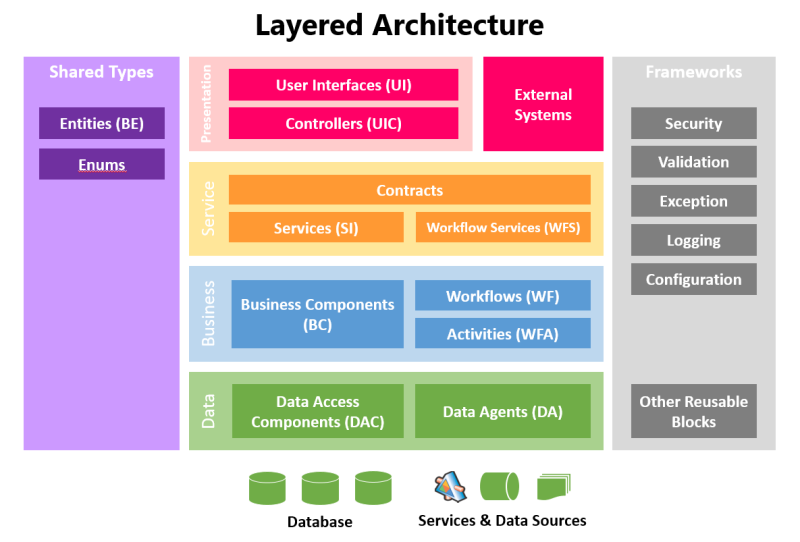
Logical/Functional Design
Logical design is the process of defining the dynamic behaviors and interaction logic between components, such as how the components interact with each other, how the data flows between components, etc. It is a high-level design that focuses on the overall architecture and organization of the system, rather than the specific details of how the components will be implemented.
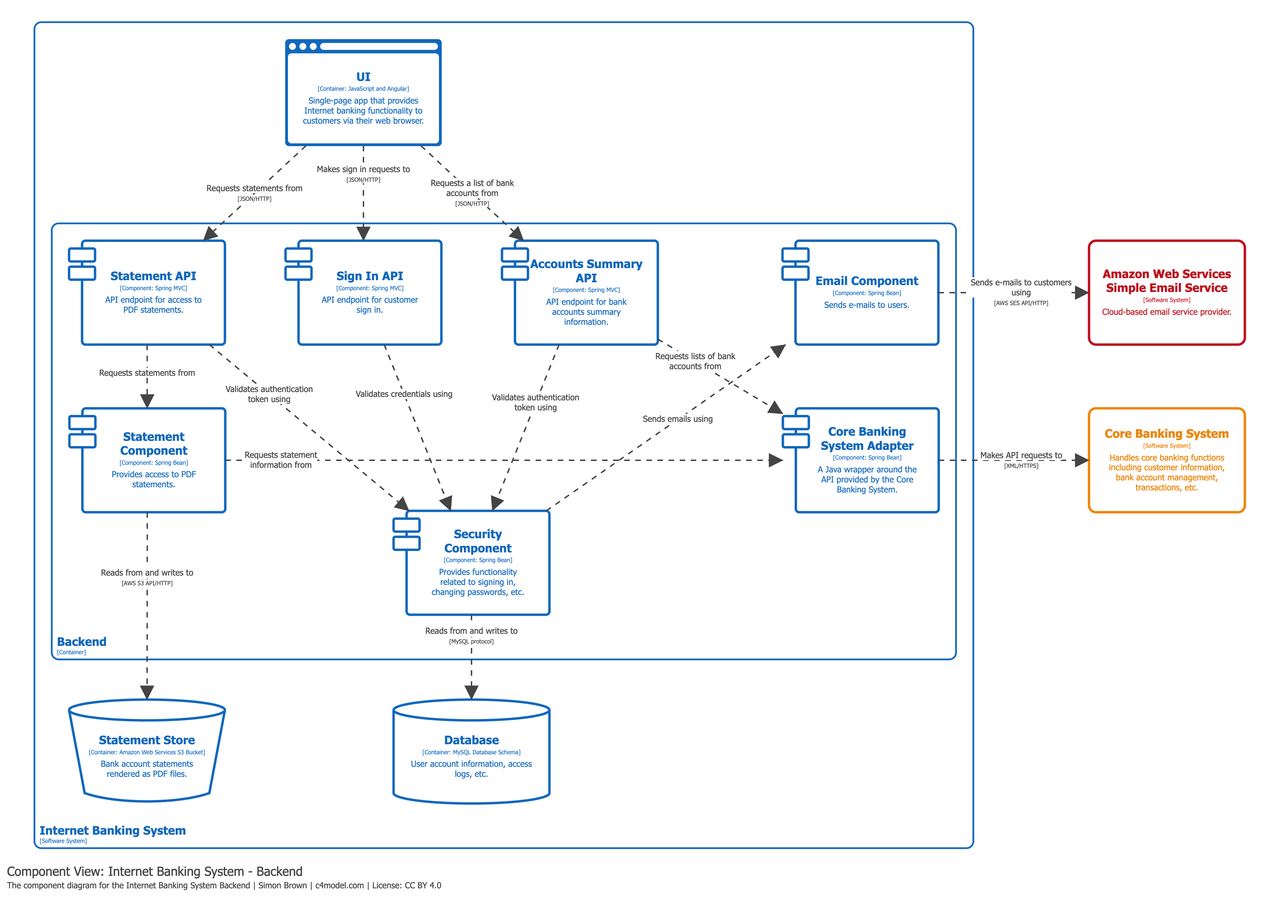
- Sketch the system architecture
- Fundamentals
- Architecture Patterns
- Monolithic Architecture (Traditional)
- Service-Oriented Architecture (SOA)
- Micro-services Architecture (MSA)
- An architectural style that structures an application using loosely coupled services
- Event-driven Architecture (EDA)
- Cloud Native (Utilize cloud services such as EC2, S3, AWS Lambda, etc.)
- System Design patterns
- Bloom filters
- Consistent hashing
- Quorum
- Checksum
- Merkle trees
- Leader election
- Data Access Patterns
- Architecture Patterns
- Components
- High cohesion and low coupling for the independence of components
- Divide by functions
- Divide by domains
- Relationship of components
- Horizontal Relationship
- Vertical Relationship
- Fundamentals
- Scale the design (Scale problems)
- Scalability refers to an application’s ability to handle and withstand an increased workload without sacrificing latency
- Identify bottlenecks (Articulate problems)
- Types
- Traffic
- Based on Read/Write Ratio, as known as IOPS (Input/output operations per second)
- Data
- Storage
- Availability
- Redundancy
- Back-up
- …
- Traffic
- Examples
- Too many user requests
- The data is too huge
- Is there a single point of failure in this system? How do we remove it?
- Do you have enough data replicas to serve the user in case you lose a few servers?
- Do we have enough copies of our services to prevent shutdown?
- Types
- Resolve bottlenecks (Come up with solutions)
- Caching
- Benefits
- Improve application performance
- Reduce database cost
- Reduce the load on the backend
- Predictable performance
- Eliminate database hotspots
- Increase read throughput and lower the data retrieval latency (IOPS, Input/Output operations per second)
- Types
- Application Caching
- CDN
- DNS
- Database Caching
- In-memory Caches
- Redis
- Memcached
- Application Caching
- Cache invalidation
- Write-through cache
- Write-around cache
- Write-back cache
- Cache Eviction
- First in first out (FIFO)
- Last in first out (LIFO)
- Least recently used (LRU)
- Most recently used (MRU)
- Least frequently used (LFU)
- Random replacement (RR)
- Benefits
- DNS (Domain Name System)
- Instances of the app server might be located in different data centers at different physical locations. We can add geolocation-based policy DNS to provide the client with a server IP address that is physically located closer to the client.
- Products
- Amazon Route 53
- CDN (Content Delivery Network)
- A content delivery network (CDN) is a globally distributed network of proxy servers, serving content from locations closer to the user. We can serve static contents via CDN to improve user experiences.
- Products
- CloudFlare
- Fastly
- Amazon CloudFront
- Load balancing
- Horizontal scaling (or scaling out)
- Means adding more machines into your pool of resources.
- Vertical scaling (or scaling up)
- Means adding more power (CPU, RAM) to your existing machine, it increases the power of the hardware running the application.
- Change database
- NoSQL database for handling high R/W ratio of QPS
- Schemaless Database
- Database optimization
- Database scaling
- Database sharding (Scale Database)
- What type of sharding key are we going to be using?
- Database replication
- Single leader replication
- All writes go to one database, reads come from any database
- Multi leader replication
- Writes can go to a small subset of leader databases, reads can come from any database
- Leaderless replication
- Writes go to all databases, reads come from all databases
- Comparison
- Single leader is useful to ensure that there are no data conflicts, all writes will go to one node
- Multi leader and leaderless replication is useful for increasing write throughput beyond just one database node (at the cost of potential write conflicts)
- Single leader replication
- Database sharding (Scale Database)
- High Concurrency
- Failure Scenarios
- Request Rate Limiter
- Circuit Breaker
- Caching
- Justify your ideas (Discuss the trade-offs of your solutions)
Detail design (LLD, Low Level Design)
Dive into details for each component, such as interface, algorithm, process, state transition, etc.
- Define the interface
- Design the data model
Related Tools:
- Program Flow Chart
- N-S Structure Diagram
- Problem Analysis Diagram (PAD)
- …
With the detailed design done, do remember to keep your design simple, things will not always go your way, so you may have to come back and make some changes on the go, as in the real-world, everything is evolving and changing.
System API Design
- What APIs would we need? It should be clear after gathering the requirements.
Return all bookshops on a user’s location.
| API | Remark |
|---|---|
| GET /v1/search/nearby |
Bookshop owner can add, delete or update a bookshop.
| API | Remark |
|---|---|
| GET /v1/bookshops | Return detailed information about all bookshops |
| GET /v1/bookshops/:id | Return detailed information about a bookshop |
| POST /v1/bookshops | Add a bookshop |
| PUT /v1/bookshops/:id | Update details of a bookshop |
| DELETE /v1/bookshops/:id | Delete a bookshop |
This part may involve the way to handle pagination, infinite scroll supporting, etc.
GET /v1/bookshops?page=1&per_page=20
- Define the input parameters and output responses carefully.
Input parameters:
| Field | Description | Type |
|---|---|---|
| Name | ABC | String |
| Author | Foo | String |
| Description | An interesting story book | String |
| Price | The book price | Float |
Output Response:
{
"total": 100,
"books": [
{
"name": "ABC",
"author": "Foo",
"price": 100.0
},
{
"name": "DFG",
"author": "Bar",
"price": 50.0
},
...
]
}
Database Schema Design
To hash out the data model and schema
| Field | Type |
|---|---|
| userId | UUID |
| Name | String |
| BOD | Timestamp |
| Remark | String |
Class Diagram Design
To design class diagram with respect OOP concepts
Implementation
SOLID Design Principles
The SOLID principles were introduced by Robert C. Martin in his 2000 paper “ Design Principles and Design Patterns”. These design principles encourage us to create more maintainable, understandable, and flexible software.
SOLID is an acronym that stands for five key design principles:
- Single Responsibility Principle (SRP)
- Testing – A class with one responsibility will have far fewer test cases.
- Lower coupling – Less functionality in a single class will have fewer dependencies.
- Organization – Smaller, well-organized classes are easier to search than monolithic ones.
- Open-closed Principle
- By extending the class, we can be sure that our existing application won’t be affected.
- Liskov Substitution Principle
- It states that a subclass should be replaceable by its base class.
- Because inheritance assumes that subclasses inherit everything from their parent class, subclasses can extend behavior but not narrow it down. Therefore, when a class violates this principle, it can lead to some nasty bugs that are hard to find.
- For example, a square inherits a rectangle, and the function to calculate the area will indirectly violate this principle. Because it violates the characteristics of the square, you can change the width and height to be unequal.
- Interface Segregation Principle
- It means interfaces remain separate, A specific interface is better than a general-purpose interface. The class shouldn’t be forced to implement functions they don’t need.
- Dependency Inversion Principle
- Our class should depend on interfaces and abstract classes instead of concrete classes and functions.
- We rely on interfaces rather than concrete classes.
All five are commonly used by software engineers and provide some important benefits for developers, which also are used to Object-Oriented class design.
Performance Optimization
- Utilize resource pools to reduce the cost of creating and recycling reusable
objects.
- Common cases:
- Thread pool
- Connection pool
- Common cases:
- Sequential read and write, reduce random IO, reduce cache miss.
- The performance of memory sequential read and write is much better than random read and write.
- Disk sequential read and write performance is much better than random read and write.
- Ordered list, a dictionary structure based on ordered arrays.
- In Java, everything is an object, so in an array, seemingly continuous objects are actually discrete in physical memory, so the traversal effect will be much worse.
- For languages such as C, C++ and so on, they all support
struct. When the object is defined as astruct, the memory occupied by an array of this type is continuous, and the traversal effect will be much better than that of Java. - Why kafka is faster, because it reads and writes disks sequentially.
- Any large-scale data problem can be settled by splitting
- Such as batching, framing, paging, time-sharing, slicing, partitioning, database sharding.
- Routing schemes can be simply divided into two categories
- Non-deterministic routing
- The same key can be mapped to different computing units for multiple routes
- It’s mostly used for distributed systems between stateless nodes
- Common solutions
- Round Robin
- Random
- Deterministic routing
- The same key must be mapped to the same computing unit no matter how many times it passes through the route
- It’s mostly used for distributed systems between stateful nodes
- Common solutions
- Range
- Hash
- Configuration table (e.g. MySQL’s List in partitioning types)
- Non-deterministic routing
- Batching
- There will be differences in capacity and performance in the IO of different components in the system.
- Read optimization relies on caching, writing optimization relies on buffering, and batching ≈ caching + buffering. A cache is a piece of memory for reading, and a buffer is a piece of memory for writing.
- The disadvantage of batching is that the data consistency is poor, whether it is caching or buffering, the same problem exists.
- Batching is one of the most important IO optimization methods whenever IO performance bottlenecks are encountered, as it has simple logic, does not involve multi-thread concurrency, has no special requirements for data structures, and has low system transformation costs.
- Framing
- Operations that will take a long time also need to be distributed to multiple frames for execution, thereby reducing the waiting time for blocking.
- The single-threaded nature of UI rendering
- The single-threaded nature of Redis
- Paging
- It can be regarded as an alternative framing operation, which can avoid the DB loading pressure and network transmission pressure caused by one-time data acquisition.
- Time-sharing
- It refers to the technology that multiple objects use the same hardware in turn, and it is more common in the underlying software that deals with hardware.
- time-sharing operating system
- time-sharing network
- I/O multiplexing
- Slicing
- Partitioning
- When only some tables in the database have a large amount of data, use the table partitioning in the same database.
- Database sharding
- The entire database has a large amount of data and high access pressure, use the database sharding
- Separation
- It’s the SRP (Single responsibility principle) of SOLID principle.
- It can reduce development and maintenance costs while increasing reusability
of functional units. - Common designs
- Read-write separation (Separate by functions)
- In a broad sense, the focus of read-write separation is: the read does not care about writing, and the write path does not care about reading. Both focus on their own function realization without making any sacrifices or concessions for the other.
- Storage-computing separation (Separate by resources)
- Cloud Native Database Architecture. In essence, it’s Microservice Architecture
- Computing nodes are stateless, storage nodes are non-computing; computing nodes scale out, storage nodes scale up.
- Although the functions were separated, but as the words in The Duck Test: If it looks like a duck, swims like a duck, and quacks like a duck, then it probably is a duck.
- Read-write separation (Separate by functions)
- Reducing
- Do not optimize prematurely, because in the initial stage of most businesses, the amount of data is very small, and performance problems are unlikely to occur in any design.
- Faster realization of business has higher priority than business running faster.
- Reduce the amount of data per processing unit, algorithmically reduced and physically reduced.
- Common solutions
- Optimizing data structures and algorithms
- Clipping data
- Java GC
- DB Archive
- Concurrency
- The utilization rate of a single machine can be improved through concurrency, and the upper limit of the overall processing capacity can be expanded through multi-machine concurrency.
- The introduction of concurrency will greatly increase the complexity of the code and increase the difficulty of maintaining data consistency. It’s often only used as the ultimate optimization method.
The average cost of access times:
- L1 Cache Ref: 0.5ns (0.5 sec)
- L2 Cache Ref: 7ns (7 sec)
- L3 Cache Ref: 25ns (25 sec)
- DRAM: 100ns (100 sec)
- SSD: 150,000ns (1.7days)
- HDD: 10,000,000ns (16.5 weeks)
- Network Storage: ~30,000,000ns (11.4 months)
- Tape Storage: 1,000,000,000ns (31.7 years)
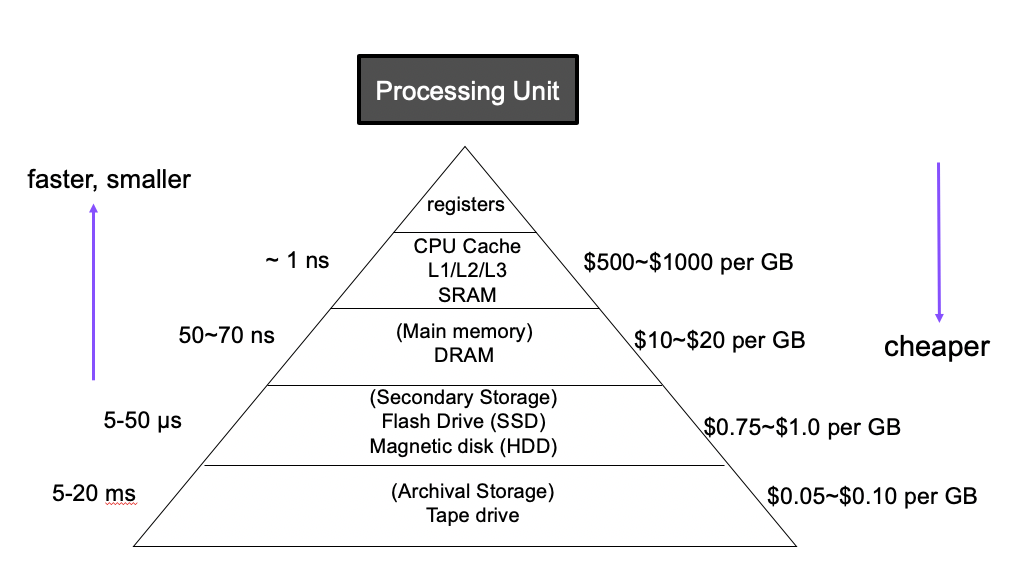
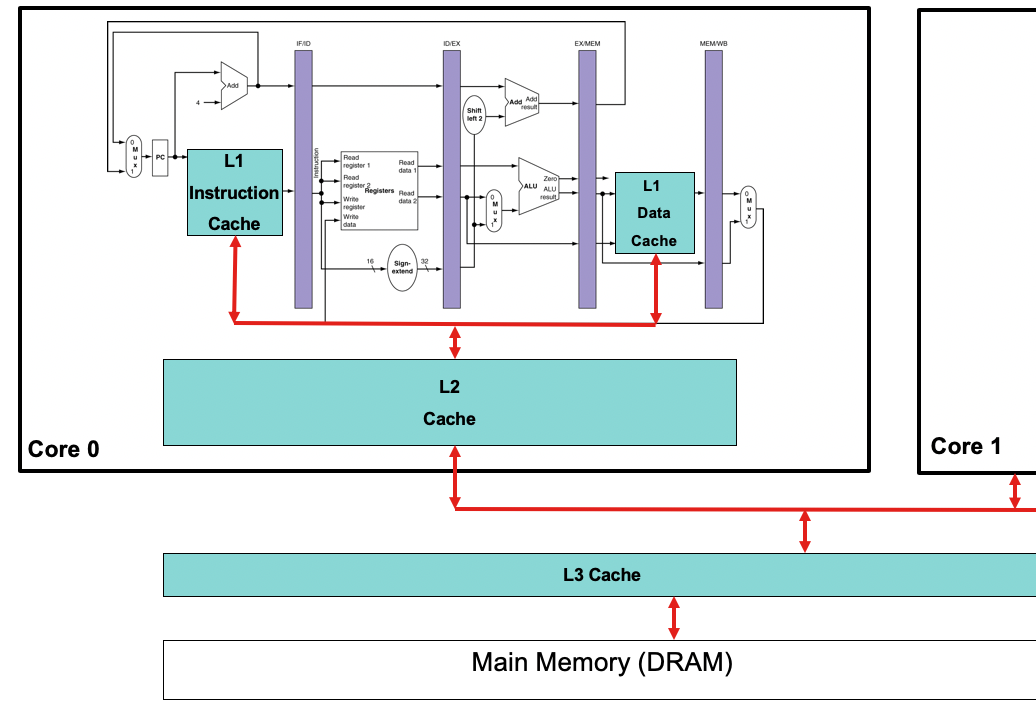
Testing (Validate the design)
Software testing is the process of executing a program in order to find bugs, so that we can verify whether the software meets various requirements. When writing a test, consider what types of defects the test needs to catch.
4 stages of V model:
- Unit Testing
- Integration Testing
- System Testing
- Acceptance Testing (Validation Testing)
Others:
- Black-box Testing
- Also known as functional testing, data-driven testing, or specification-based testing.
- Mainly to test the function of the application.
- for most software tests, such as integration testing, system testing, etc.
- White-box Testing
- Also known as glass box testing, structural testing, logic-driven testing or testing based on the program itself.
- Mainly to test the internal structure or operation of the application.
- For unit testing, integration testing.
The philosophy of testing:
- Unit Testing: To test the smallest independent piece of code to prevent regressions.
- Integration Testing: The outside world is a messy place, things usually go wrong on the edge, as the place of interaction is usually where the unexpected happens.
Integration testing and unit testing are the cornerstones of robust software. When considering adding unit testing to existing software, there are costs and benefits to consider. If your code is working, if the code rarely needs to be modified, and if the code is not easily unit-testable, then the benefits of incorporating unit tests may not justify the cost. In these cases, integration tests can be relied upon to prevent defects in this area.
Testing Pyramid:

Key concepts:
- Write tests at different granularities
- The higher the level, the fewer tests you should write
Test automation strategy:
- Unite Testing (DEV)
- Component Testing (DEV+QA)
- Integration Testing (DEV+QA)
- End-to-End (E2E) Testing (QA)
Conclusion
It’s important to keep in mind that system design is an iterative process, and the design may change as new information is gathered and requirements evolve. Additionally, it’s important to communicate the design effectively to all stakeholders, including developers, users, and stakeholders, to ensure that the system meets their needs and expectations.